


Р’ СҖСғРұСҖРёРәСғ "РһРұРҫСҖСғРҙРҫРІР°РҪРёРө Рё СӮРөС…РҪРҫР»РҫРіРёРё" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№
 РЎСӮР°СӮСҢСҸ РҪРө излагаРөСӮ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСғСҺ РәРҫРҪСҶРөРҝСҶРёСҺ СҒРҫРІСҖРөРјРөРҪРҪРҫРіРҫ Рё СғР¶ СӮРөРј РұРҫР»РөРө РІСҒСҸРәРҫРіРҫ РұСғРҙСғСүРөРіРҫ РјРөРҙиааСҖС…РёРІР°. РЎРҫРҙРөСҖжаРҪРёРө СҒСӮР°СӮСҢРё СҒРІРҫРҙРёСӮСҒСҸ Рә РҝРөСҖРөСҮРёСҒР»РөРҪРёСҺ РҪРөСҒРәРҫР»СҢРәРёС… РҝРҫСҮСӮРё СҒР»СғСҮайРҪРҫ РІСӢРұСҖР°РҪРҪСӢС… РҝСҖРҫРұР»РөРј, РәРҫСӮРҫСҖСӢРө РҪРөРёР·РұРөР¶РҪРҫ РІРҫР·РҪРёРәРҪСғСӮ РҝСҖРё РәРҫРҪСҒСӮСҖСғРёСҖРҫРІР°РҪРёРё, СҖазСҖР°РұРҫСӮРәРө Рё РІРҪРөРҙСҖРөРҪРёРё СҶРёС„СҖРҫРІРҫРіРҫ РјРөРҙиааСҖС…РёРІР° РІ СҖРөалСҢРҪРҫРө РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРҫ. РЎР»СғСҮайРҪРҫСҒСӮСҢ РІСӢРұРҫСҖР° РҫРҝСҖРөРҙРөР»СҸРөСӮСҒСҸ СӮРөРј, СҮСӮРҫ РҝРҫ РұРҫР»СҢСҲРөР№ СҮР°СҒСӮРё РұСғРҙСғСӮ СҖР°СҒСҒРјРҫСӮСҖРөРҪСӢ СӮРҫР»СҢРәРҫ СӮРө РҝСҖРҫРұР»РөРјСӢ, СҒ РәРҫСӮРҫСҖСӢРјРё РІ СӮРөР»РөРәРҫРјРҝР°РҪРёРё "РҡСғР»СҢСӮСғСҖР°" СғР¶Рө СғСҒРҝРөли СҒСӮРҫР»РәРҪСғСӮСҢСҒСҸ РҪР° СҒРҫРұСҒСӮРІРөРҪРҪРҫР№ РҝСҖР°РәСӮРёРәРө. РҹРҫ РәажРҙРҫР№ СҖР°СҒСҒРјР°СӮСҖРёРІР°РөРјРҫР№ РҝСҖРҫРұР»РөРјРө РҙР°РөСӮСҒСҸ РәРҫРјРјРөРҪСӮР°СҖРёР№, СҶРөР»СҢ РәРҫСӮРҫСҖРҫРіРҫ - РҝСҖРёРІРөСҒСӮРё РҙРҫРәазаСӮРөР»СҢСҒСӮРІР°, СғРұРөР¶РҙР°СҺСүРёРө РІ СҒСғСүРөСҒСӮРІРҫРІР°РҪРёРё РҝСҖРҫРұР»РөРј, Рё РҪамРөСӮРёСӮСҢ РҝСғСӮРё РёС… СҖРөСҲРөРҪРёСҸ
РЎСӮР°СӮСҢСҸ РҪРө излагаРөСӮ РҝРҫСҒР»РөРҙРҫРІР°СӮРөР»СҢРҪСғСҺ РәРҫРҪСҶРөРҝСҶРёСҺ СҒРҫРІСҖРөРјРөРҪРҪРҫРіРҫ Рё СғР¶ СӮРөРј РұРҫР»РөРө РІСҒСҸРәРҫРіРҫ РұСғРҙСғСүРөРіРҫ РјРөРҙиааСҖС…РёРІР°. РЎРҫРҙРөСҖжаРҪРёРө СҒСӮР°СӮСҢРё СҒРІРҫРҙРёСӮСҒСҸ Рә РҝРөСҖРөСҮРёСҒР»РөРҪРёСҺ РҪРөСҒРәРҫР»СҢРәРёС… РҝРҫСҮСӮРё СҒР»СғСҮайРҪРҫ РІСӢРұСҖР°РҪРҪСӢС… РҝСҖРҫРұР»РөРј, РәРҫСӮРҫСҖСӢРө РҪРөРёР·РұРөР¶РҪРҫ РІРҫР·РҪРёРәРҪСғСӮ РҝСҖРё РәРҫРҪСҒСӮСҖСғРёСҖРҫРІР°РҪРёРё, СҖазСҖР°РұРҫСӮРәРө Рё РІРҪРөРҙСҖРөРҪРёРё СҶРёС„СҖРҫРІРҫРіРҫ РјРөРҙиааСҖС…РёРІР° РІ СҖРөалСҢРҪРҫРө РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРҫ. РЎР»СғСҮайРҪРҫСҒСӮСҢ РІСӢРұРҫСҖР° РҫРҝСҖРөРҙРөР»СҸРөСӮСҒСҸ СӮРөРј, СҮСӮРҫ РҝРҫ РұРҫР»СҢСҲРөР№ СҮР°СҒСӮРё РұСғРҙСғСӮ СҖР°СҒСҒРјРҫСӮСҖРөРҪСӢ СӮРҫР»СҢРәРҫ СӮРө РҝСҖРҫРұР»РөРјСӢ, СҒ РәРҫСӮРҫСҖСӢРјРё РІ СӮРөР»РөРәРҫРјРҝР°РҪРёРё "РҡСғР»СҢСӮСғСҖР°" СғР¶Рө СғСҒРҝРөли СҒСӮРҫР»РәРҪСғСӮСҢСҒСҸ РҪР° СҒРҫРұСҒСӮРІРөРҪРҪРҫР№ РҝСҖР°РәСӮРёРәРө. РҹРҫ РәажРҙРҫР№ СҖР°СҒСҒРјР°СӮСҖРёРІР°РөРјРҫР№ РҝСҖРҫРұР»РөРјРө РҙР°РөСӮСҒСҸ РәРҫРјРјРөРҪСӮР°СҖРёР№, СҶРөР»СҢ РәРҫСӮРҫСҖРҫРіРҫ - РҝСҖРёРІРөСҒСӮРё РҙРҫРәазаСӮРөР»СҢСҒСӮРІР°, СғРұРөР¶РҙР°СҺСүРёРө РІ СҒСғСүРөСҒСӮРІРҫРІР°РҪРёРё РҝСҖРҫРұР»РөРј, Рё РҪамРөСӮРёСӮСҢ РҝСғСӮРё РёС… СҖРөСҲРөРҪРёСҸ
РһСҒРҫРұРөРҪРҪРҫСҒСӮРё РҝРөСҖРөС…РҫРҙР° РҪР° СҶРёС„СҖСғ
Рҡ РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮСғ РҫСӮРҪРҫСҒРёСӮСҒСҸ СҲРёСҖРҫРәРёР№ СҒРҝРөРәСӮСҖ РёСҒРҝРҫР»СҢР·СғРөРјСӢС… РІ РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё РјР°СӮРөСҖиалРҫРІ СҒамСӢС… СҖазРҪРҫРҫРұСҖазРҪСӢС… СӮРёРҝРҫРІ Рё С„РҫСҖРјР°СӮРҫРІ (СҮРёСҒР»РҫРІСӢРө РҙР°РҪРҪСӢРө, СӮРөРәСҒСӮ/РіРёРҝРөСҖСӮРөРәСҒСӮ, РҙРІСғС…-Рё СӮСҖРөС…РјРөСҖРҪР°СҸ РіСҖафиРәР° Рё РёР·РҫРұСҖажРөРҪРёСҸ, Р·РІСғРә, РІРёРҙРөРҫ, РәРёРҪРҫ Рё РјРҪРҫРіРҫРө РҙСҖСғРіРҫРө). Р—РІСғРә, РІРёРҙРөРҫ, РәРёРҪРҫ Рё РҪРөРәРҫСӮРҫСҖСӢРө РҙСҖСғРіРёРө РІ СҒРёР»Сғ РёС… СҒРҝРөСҶифиРәРё РҫРұСҖазСғСҺСӮ РҫСӮРҙРөР»СҢРҪСӢР№ РәлаСҒСҒ РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР° - movie, РөСҒли РҝСҖРёРҙРөСҖживаСӮСҢСҒСҸ СӮРөСҖРјРёРҪРҫР»РҫРіРёРё, РІРІРөРҙРөРҪРҪРҫР№ РҫРҙРҪРёРј РёР· РәР»СҺСҮРөРІСӢС… СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРёС… "РёРіСҖРҫРәРҫРІ" -РәРҫРјРҝР°РҪРёРөР№ Apple Computer. РӯСӮРҫ РәлаСҒСҒ РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР° РҫРәазалСҒСҸ РҝРҫСҒР»РөРҙРҪРёРј, РІРҫРІР»РөСҮРөРҪРҪСӢРј РІ СҶРёС„СҖРҫРІСғСҺ СҖРөРІРҫР»СҺСҶРёСҺ, РҪР°СҮавСҲСғСҺСҒСҸ РІ РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё РІ СҒРөРјРёРҙРөСҒСҸСӮСӢРө РіРҫРҙСӢ РҝСҖРҫСҲР»РҫРіРҫ СҒСӮРҫР»РөСӮРёСҸ СҒ РҝРҫСҸРІР»РөРҪРёРөРј СҚР»РөРәСӮСҖРҫРҪРҪСӢС… РёР·РҙР°СӮРөР»СҢСҒРәРёС… СҒРёСҒСӮРөРј.
РҹСҖРҫРҪРёРәРҪРҫРІРөРҪРёРө СҶРёС„СҖСӢ РҪР°СҮалРҫСҒСҢ СҒ РІРҪРөРҙСҖРөРҪРёСҸ СҶРёС„СҖРҫРІСӢС… С„РҫСҖРјР°СӮРҫРІ РҪР° РҫСӮРҙРөР»СҢРҪСӢС… СҒСӮР°РҙРёСҸС… РјРөРҙРёР°РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР° - СҒРҫРұСҒСӮРІРөРҪРҪРҫ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРҫ, СҖРөРҙР°РәСӮРёСҖРҫРІР°РҪРёРө, С…СҖР°РҪРөРҪРёРө Рё РҙРҫСҒСӮавРәР° Р·РІСғРәР°, РІРёРҙРөРҫ Рё РәРёРҪРҫ (РұРөР· СҒРәРҫР»СҢРәРҫ-РҪРёРұСғРҙСҢ СҒСғСүРөСҒСӮРІРөРҪРҪСӢС… РёР·РјРөРҪРөРҪРёР№ СҒамих СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРёС… РҝСҖРҫСҶРөСҒСҒРҫРІ). РҹРҫР»РҪРҫРјР°СҒСҲСӮР°РұРҪРҫРө РҝСҖРҫРҪРёРәРҪРҫРІРөРҪРёРө СҒРҫРІСҖРөРјРөРҪРҪСӢС… РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢС… Рё СӮРөР»РөРәРҫРјРјСғРҪРёРәР°СҶРёРҫРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёР№ РІ СҒРөРәСӮРҫСҖР° РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё, РёРјРөСҺСүРёРө РҙРөР»Рҫ СҒ movie, - РҝСҖР°РәСӮРёРәР° СғР¶Рө РҝРҫСҒР»РөРҙРҪРөРіРҫ РҙРөСҒСҸСӮРёР»РөСӮРёСҸ. РЈР¶Рө СҖазСҖР°РұРҫСӮР°РҪСӢ Рё СҲРёСҖРҫРәРҫ РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ СҮР°СҒСӮРҪСӢРө СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРёРө СҖРөСҲРөРҪРёСҸ РҝРҫ СғРҝСҖавлРөРҪРёСҺ Рё РҫРұСҖР°РұРҫСӮРәРө СҶРёС„СҖРҫРІРҫРіРҫ movie-РәРҫРҪСӮРөРҪСӮР°, Рё СҒР»РөРҙСғСҺСүРёР№ РҫжиРҙР°РөРјСӢР№ СҲаг - СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәР°СҸ РёРҪСӮРөРіСҖР°СҶРёСҸ РҫСӮРҙРөР»СҢРҪСӢС… СҖРөСҲРөРҪРёР№ РІ РөРҙРёРҪСӢРө РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪРҫ-РәРҫРјРјСғРҪРёРәР°СҶРёРҫРҪРҪСӢРө РәРҫРјРҝР»РөРәСҒСӢ, РҫСӮРІРөСҮР°СҺСүРёРө СӮСҖР°РҙРёСҶРёРҫРҪРҪСӢРј РұРёР·РҪРөСҒ-Р·Р°РҙР°СҮам РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё РҪР° РҪРҫРІРҫРј СғСҖРҫРІРҪРө Рё РҝРҫР·РІРҫР»СҸСҺСүРёРө СҒСӮавиСӮСҢ РҪРҫРІСӢРө Р·Р°РҙР°СҮРё.
 Рҡ РҪРёРј РҫСӮРҪРҫСҒРёСӮСҒСҸ, РҪР°РҝСҖРёРјРөСҖ, СҒРҫР·РҙР°РҪРёРө СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРҫР№ Рё РұРёР·РҪРөСҒ-РёРҪС„СҖР°СҒСӮСҖСғРәСӮСғСҖ РҙР»СҸ РҝСҖРҫРҙажи movie-РәРҫРҪСӮРөРҪСӮР°. РһСҒРҫРұРөРҪРҪРҫ СҚСӮРҫ РәР°СҒР°РөСӮСҒСҸ РІРёРҙРөРҫРәРҫРҪСӮРөРҪСӮР°. Р•СҒли РіРҫРҙРҫРІРҫР№ РјРёСҖРҫРІРҫР№ РҫРұСҠРөРј РҝСҖРҫРҙаж С„РҫСӮРҫР°СҖС…РёРІРҫРІ РҝСҖРөРІСӢСҲР°РөСӮ 2 РјР»СҖРҙ РҙРҫллаСҖРҫРІ РҝСҖРё 20%-РҪРҫРј РіРҫРҙРҫРІРҫРј СҖРҫСҒСӮРө, СӮРҫ РІРёРҙРөРҫР°СҖС…РёРІ РҝСҖРҫРҙР°РөСӮСҒСҸ, РҝРҫ СҖазРҪСӢРј РҫСҶРөРҪРәам, РҫСӮ 140 РҙРҫ 400 РјР»РҪ РҙРҫллаСҖРҫРІ РІ РіРҫРҙ. РһРҙРҪР°РәРҫ Johnathan Klein, РҫСҒРҪРҫРІР°СӮРөР»СҢ Рё РіРөРҪРөСҖалСҢРҪСӢР№ РҙРёСҖРөРәСӮРҫСҖ РәРҫРјРҝР°РҪРёРё Getty Images, РәСҖСғРҝРҪРөР№СҲРөРіРҫ РІ РјРёСҖРө РҝСҖРҫРҙавСҶР° Р°СҖС…РёРІРҪСӢС… С„РҫСӮРҫРјР°СӮРөСҖиалРҫРІ (Р° РІ РҝРҫСҒР»РөРҙРҪРөРө РІСҖРөРјСҸ Рё РІРёРҙРөРҫ), СғСӮРІРөСҖР¶РҙР°РөСӮ, СҮСӮРҫ РҝРҫ РҫРұСҠРөРјСғ РҝСҖРҫРҙаж Р°СҖС…РёРІРҪРҫРө РІРёРҙРөРҫ РІ РұлижайСҲРёРө РіРҫРҙСӢ РҙРҫРіРҫРҪРёСӮ Р°СҖС…РёРІРҪРҫРө С„РҫСӮРҫ. РқРҫ РҪРё РҝСҖРҫРҙажи, РҪРё РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРҫ РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР° РҪРө РұСғРҙСғСӮ СҚффРөРәСӮРёРІРҪСӢРјРё, РөСҒли РҪРө РҫРұРөСҒРҝРөСҮРёСӮСҢ СҚффРөРәСӮРёРІРҪСӢР№ РҝРҫРёСҒРә РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР°.
Рҡ РҪРёРј РҫСӮРҪРҫСҒРёСӮСҒСҸ, РҪР°РҝСҖРёРјРөСҖ, СҒРҫР·РҙР°РҪРёРө СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРҫР№ Рё РұРёР·РҪРөСҒ-РёРҪС„СҖР°СҒСӮСҖСғРәСӮСғСҖ РҙР»СҸ РҝСҖРҫРҙажи movie-РәРҫРҪСӮРөРҪСӮР°. РһСҒРҫРұРөРҪРҪРҫ СҚСӮРҫ РәР°СҒР°РөСӮСҒСҸ РІРёРҙРөРҫРәРҫРҪСӮРөРҪСӮР°. Р•СҒли РіРҫРҙРҫРІРҫР№ РјРёСҖРҫРІРҫР№ РҫРұСҠРөРј РҝСҖРҫРҙаж С„РҫСӮРҫР°СҖС…РёРІРҫРІ РҝСҖРөРІСӢСҲР°РөСӮ 2 РјР»СҖРҙ РҙРҫллаСҖРҫРІ РҝСҖРё 20%-РҪРҫРј РіРҫРҙРҫРІРҫРј СҖРҫСҒСӮРө, СӮРҫ РІРёРҙРөРҫР°СҖС…РёРІ РҝСҖРҫРҙР°РөСӮСҒСҸ, РҝРҫ СҖазРҪСӢРј РҫСҶРөРҪРәам, РҫСӮ 140 РҙРҫ 400 РјР»РҪ РҙРҫллаСҖРҫРІ РІ РіРҫРҙ. РһРҙРҪР°РәРҫ Johnathan Klein, РҫСҒРҪРҫРІР°СӮРөР»СҢ Рё РіРөРҪРөСҖалСҢРҪСӢР№ РҙРёСҖРөРәСӮРҫСҖ РәРҫРјРҝР°РҪРёРё Getty Images, РәСҖСғРҝРҪРөР№СҲРөРіРҫ РІ РјРёСҖРө РҝСҖРҫРҙавСҶР° Р°СҖС…РёРІРҪСӢС… С„РҫСӮРҫРјР°СӮРөСҖиалРҫРІ (Р° РІ РҝРҫСҒР»РөРҙРҪРөРө РІСҖРөРјСҸ Рё РІРёРҙРөРҫ), СғСӮРІРөСҖР¶РҙР°РөСӮ, СҮСӮРҫ РҝРҫ РҫРұСҠРөРјСғ РҝСҖРҫРҙаж Р°СҖС…РёРІРҪРҫРө РІРёРҙРөРҫ РІ РұлижайСҲРёРө РіРҫРҙСӢ РҙРҫРіРҫРҪРёСӮ Р°СҖС…РёРІРҪРҫРө С„РҫСӮРҫ. РқРҫ РҪРё РҝСҖРҫРҙажи, РҪРё РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРҫ РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР° РҪРө РұСғРҙСғСӮ СҚффРөРәСӮРёРІРҪСӢРјРё, РөСҒли РҪРө РҫРұРөСҒРҝРөСҮРёСӮСҢ СҚффРөРәСӮРёРІРҪСӢР№ РҝРҫРёСҒРә РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР°.
РЎРөРәСӮРҫСҖР° "РҪРҫРІРҫР№" РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё
ГлавРҪСӢРјРё РҝСҖРҫРёР·РІРҫРҙРёСӮРөР»СҸРјРё, "С…СҖР°РҪРёСӮРөР»СҸРјРё" Рё РҝРҫСӮСҖРөРұРёСӮРөР»СҸРјРё Р·РІСғРәР°, РІРёРҙРөРҫ, РәРёРҪРҫ Рё РҙСҖСғРіРёС… movie-СӮРёРҝРҫРІ РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮР°, РұРөР·СғСҒР»РҫРІРҪРҫ, СҸРІР»СҸСҺСӮСҒСҸ РјРөРҙРёР°РәРҫРјРҝР°РҪРёРё РІ СӮСҖР°РҙРёСҶРёРҫРҪРҪРҫРј РёС… РҝРҫРҪРёРјР°РҪРёРё. Р’ ЕвСҖРҫРҝРө Рё РЎРЁРҗ РҪР°СҒСҮРёСӮСӢРІР°РөСӮСҒСҸ 50 000 РјРөРҙРёР°РәРҫРјРҝР°РҪРёР№, СҒРҫСҒСӮавлСҸСҺСүРёС… РҫРҙРёРҪ РёР· РәР»СҺСҮРөРІСӢС… СҒРөРәСӮРҫСҖРҫРІ РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё, РІ РәРҫСӮРҫСҖРҫРј Р·Р°РҪСҸСӮРҫ 8 000 000 СҮРөР»РҫРІРөРә (GI-STICS Research). РқРҫ СҒРҫРұСҒСӮРІРөРҪРҪРҫ РјРөРҙРёР°РәРҫРјРҝР°РҪРёРё - РҙалРөРәРҫ РҪРө РөРҙРёРҪСҒСӮРІРөРҪРҪР°СҸ РәР°СӮРөРіРҫСҖРёСҸ РәРҫРјРҝР°РҪРёР№, РҫСҖРёРөРҪСӮРёСҖРҫРІР°РҪРҪСӢС… РҪР° movie-РәРҫРҪСӮРөРҪСӮ.
Р”СҖСғРіР°СҸ РұРҫР»СҢСҲР°СҸ Рё РҪРҫРІР°СҸ РәР°СӮРөРіРҫСҖРёСҸ -РәСҖСғРҝРҪСӢРө РәРҫСҖРҝРҫСҖР°СҶРёРё, СҖР°РұРҫСӮР°СҺСүРёРө РҪР° РјР°СҒСҒРҫРІРҫРј СҖСӢРҪРәРө, Рё РіРҫСҒСғРҙР°СҖСҒСӮРІРөРҪРҪСӢРө СғСҮСҖРөР¶РҙРөРҪРёСҸ. РӯСӮРҫ РҪРҫРІР°СҸ СӮРөРҪРҙРөРҪСҶРёСҸ РұСӢла РҪазваРҪР° New Media Model. Р’ СҒСӮР°СӮСҢРө J. Michael "Embrace Media or Die" (Р¶СғСҖРҪал "Worth", РјР°СҖСӮ 2001 РіРҫРҙР°) РҫРұСҠСҸСҒРҪСҸРөСӮСҒСҸ, РҝРҫСҮРөРјСғ СҒ РҝРөСҖРөС…РҫРҙРҫРј РҪР° РҫРҪлайРҪРҫРІСӢРө РҝСҖРҫРҙажи РәСҖСғРҝРҪСӢРө РәРҫСҖРҝРҫСҖР°СҶРёРё РҪР°РҪРёРјР°СҺСӮ РҝСҖРҫРҙСҺСҒРөСҖРҫРІ РёР· Р“РҫлливСғРҙР° Рё РІСӢРҪСғР¶РҙРөРҪРҪРҫ СҒСӮР°РҪРҫРІСҸСӮСҒСҸ РјРөРҙРёР°РәРҫРјРҝР°РҪРёСҸРјРё. Р’ РәР°СҮРөСҒСӮРІРө РҝСҖРёРјРөСҖРҫРІ РҝСҖРёРІРөРҙРөРҪСӢ СҒСӮРҫР»СҢ СҖазлиСҮРҪСӢРө РәРҫРјРҝР°РҪРёРё, РәР°Рә Nike, Ford Motors Рё Charles Schwab Рё РҙСҖСғРіРёРө РёР·РІРөСҒСӮРҪСӢРө РёР· СҒРҝРёСҒРәР° Fortune 500. Р’ СҶРөР»РҫРј СҒРҝРёСҒРҫРә РәРҫРјРҝР°РҪРёР№, РҝСҖРҫРёР·РІРҫРҙСҸСүРёС… Рё/или "С…СҖР°РҪСҸСүРёС…", Рё/или РҝРҫСӮСҖРөРұР»СҸСҺСүРёС… РұРҫР»СҢСҲРёРө РҫРұСҠРөРјСӢ РІРёРҙРөРҫ-Рё РёРҪРҫР№ movie-РёРҪС„РҫСҖРјР°СҶРёРё, РІРөСҒСҢРјР° РҫРұСҲРёСҖРөРҪ:
РҡРҫРјРҝР°РҪРёРё РІСҒРөС… СӮРёРҝРҫРІ РҪСғР¶РҙР°СҺСӮСҒСҸ РІ "РҝСҖавилСҢРҪСӢС…" СҶРёС„СҖРҫРІСӢС… РјРөРҙРёР°СҖхивах.
РҹРҫСӮСҖРөРұРҪРҫСҒСӮРё РјРөРҙиаиРҪРҙСғСҒСӮСҖРёРё
РқР° СҒРөРіРҫРҙРҪСҸ, РІ СғСҒР»РҫРІРёСҸС… РҝСҖРёРҪСҶРёРҝиалСҢРҪРҫР№ РіРҫСӮРҫРІРҪРҫСҒСӮРё СӮРөС…РҪРҫР»РҫРіРёСҮРөСҒРәРёС… СҖРөСҲРөРҪРёР№ Рә РІРҪРөРҙСҖРөРҪРёСҺ, РІ РҝРҫРҙавлСҸСҺСүРөРј РұРҫР»СҢСҲРёРҪСҒСӮРІРө РјРөРҙРёР°РәРҫРјРҝР°РҪРёР№ РҫСҒСӮР°СҺСӮСҒСҸ РҪРөСҖРөСҲРөРҪРҪСӢРјРё РјРҪРҫРіРёРө РҪР°СҒСғСүРҪСӢРө Р·Р°РҙР°СҮРё:
Р•СҒли РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮ РәР°Рә-СӮРҫ Рё РҫРҝРёСҒР°РҪ, СӮРҫ СҒамСӢРј РҝСҖРҫСҒСӮСӢРј Рё РҪРөСҚффРөРәСӮРёРІРҪСӢРј РҙР»СҸ РҝРҫРёСҒРәР° СҒРҝРҫСҒРҫРұРҫРј, СҮСӮРҫ СӮРҫР¶Рө РҪРө СҒРҝРҫСҒРҫРұСҒСӮРІСғРөСӮ РҝРҫРёСҒРәСғ Рё РҝСҖРҫРҙажРө РәРҫРҪСӮРөРҪСӮР°.
РңРҫР¶РҪРҫ СғСҒР»СӢСҲР°СӮСҢ РјРҪРҫРіРҫСҮРёСҒР»РөРҪРҪСӢРө РІРҫРҝСҖРҫСҒСӢ Рё РҙиалРҫРіРё, СӮРёРҝРёСҮРҪСӢРө РҙР»СҸ СҒРөРіРҫРҙРҪСҸСҲРҪРөРіРҫ СҒРҫСҒСӮРҫСҸРҪРёСҸ РҫСӮСҖР°СҒли, РҝРҫРҙРҫРұРҪСӢРө РҪРёР¶РөРҝРөСҖРөСҮРёСҒР»РөРҪРҪСӢРј:
Р’РөРҙСғСүР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ: РјРҫСӮРёРІСӢ
РҹСҖРё РІСҒРөР№ СҖазСғРјРҪРҫСҒСӮРё Рё РҫРұРҫСҒРҪРҫРІР°РҪРҪРҫСҒСӮРё РҙлиРҪРҪСӢС… СҒРҝРёСҒРәРҫРІ С„СғРҪРәСҶРёРҫРҪалСҢРҪСӢС… СӮСҖРөРұРҫРІР°РҪРёР№ Рә РјРөРҙиааСҖхивам РұСӢР»Рҫ РұСӢ РҝСҖавилСҢРҪРҫ РІСӢРҙРөлиСӮСҢ РҪРөРәСғСҺ РІРөРҙСғСүСғСҺ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ, Р¶РөлаСӮРөР»СҢРҪРҫ РІ РәРҫлиСҮРөСҒСӮРІРө "РҫРҙРҪР° СҲСӮСғРәР°". РқРөРҫРұС…РҫРҙРёРјРҫСҒСӮСҢ РІСӢРҙРөР»РөРҪРёСҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮРё в„– 1 СҸРІР»СҸРөСӮСҒСҸ СҒРҫРҫРұСҖажРөРҪРёРөРј СҒамРҫРіРҫ РҫРұСүРөРіРҫ СҒРІРҫР№СҒСӮРІР°, РҪР°СҒСӮРҫР»СҢРәРҫ РҫРұСүРөРіРҫ, СҮСӮРҫ РәР°Рә-СӮРҫ РҪРөР»РҫРІРәРҫ РҫСҮРөСҖРөРҙРҪРҫР№ СҖаз РҪР°СҒСӮаиваСӮСҢ РҪР° СҚСӮРҫРј. РқРҫ, Рә СҒРҫжалРөРҪРёСҺ, РҫРұСүРөРёР·РІРөСҒСӮРҪРҫСҒСӮСҢ СҒРҫРҫРұСҖажРөРҪРёСҸ РөСүРө РҪРө РҫР·РҪР°СҮР°РөСӮ РөРіРҫ РҫРұСҸР·Р°СӮРөР»СҢРҪРҫСҒСӮСҢ - РҪР°СҲР° СҒРҫРұСҒСӮРІРөРҪРҪР°СҸ РҝСҖР°РәСӮРёРәР° Рё, РҪР°СҒРәРҫР»СҢРәРҫ РјСӢ РјРҫгли РҝРҫРҪСҸСӮСҢ, РҝСҖР°РәСӮРёРәР° РҙСҖСғРіРёС… РәРҫРјРҝР°РҪРёР№ РҝРҫРәазСӢРІР°РөСӮ, СҮСӮРҫ РҝСҖРөРҪРөРұСҖРөР¶РөРҪРёРө РҫРұСүРөРёР·РІРөСҒСӮРҪСӢРјРё Рё РҝРҫСӮРҫРјСғ, РәазалРҫСҒСҢ РұСӢ, РҫРұСҸР·Р°СӮРөР»СҢРҪСӢРјРё СҒРҫРҫРұСҖажРөРҪРёСҸРјРё РІСӢР·СӢРІР°РөСӮ СҒСӮРҫР»СҢ Р¶Рө РҫРұСҸР·Р°СӮРөР»СҢРҪСӢРө РҫСҲРёРұРәРё Рё СғР¶ СӮРҫСҮРҪРҫ РҝСҖРёРІРҫРҙРёСӮ Рә РұРөСҒРҝР»РҫРҙРҪСӢРј РҙРёСҒРәСғСҒСҒРёСҸРј. Рҡ СӮРҫРјСғ Р¶Рө РјСӢ СҒР»РөРҙСғРөРј СҒРҫРІРөСӮСғ РҪР°СҲРөРіРҫ СҒСӮР°СҖСҲРөРіРҫ РјРҫСҒРәРҫРІСҒРәРҫРіРҫ РәРҫллРөРіРё: "Р•СҒли РІСӢ С…РҫСӮРёСӮРө, СҮСӮРҫРұСӢ РІР°СҲРё Р°СҖРіСғРјРөРҪСӮСӢ РұСӢли РҝСҖРёРҪСҸСӮСӢ, СӮРҫ РҫРҙРҪРҫ Рё СӮРҫ Р¶Рө, РҙР»СҸ РҫРҙРҪРҫР№ Рё СӮРҫР№ Р¶Рө Р°СғРҙРёСӮРҫСҖРёРё СҒР»РөРҙСғРөСӮ РҝРҫРІСӮРҫСҖРёСӮСҢ 9 СҖаз (9 - СҮРёСҒР»Рҫ СҚРәСҒРҝРөСҖРёРјРөРҪСӮалСҢРҪРҫРө)".
РҹРөСҖРІР°СҸ РҝСҖРёСҮРёРҪР°, РҝРҫ РәРҫСӮРҫСҖРҫР№ РІРөРҙСғСүР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ РҙРҫлжРҪР° РұСӢСӮСҢ РҫРұСҸР·Р°СӮРөР»СҢРҪРҫ РҫРұСҠСҸРІР»РөРҪР° Рё РҝСҖРёРҪСҸСӮР° Рә РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҺ, РҝСҖРҫСҒСӮР° Рё РҫСҮРөРІРёРҙРҪР°: Р»СғСҮСҲРө, РөСҒли СҒРёСҒСӮРөРјР° СғРҝСҖавлРөРҪРёСҸ РјРөРҙиааСҖС…РёРІРҫРј РұСғРҙРөСӮ С…РҫСҖРҫСҲРҫ РІСӢРҝРҫР»РҪСҸСӮСҢ РҫРҙРҪСғ Р·Р°РҙР°СҮСғ, РҪРөР¶Рөли РјРҪРҫРіРҫ, РҪРҫ РҝР»РҫС…Рҫ. Р’РҫРҝСҖРҫСҒ СӮРҫР»СҢРәРҫ РІ СӮРҫРј - РәР°РәСғСҺ Р·Р°РҙР°СҮСғ.
РқР° РҝРөСҖРІСӢР№ РІР·РіР»СҸРҙ СҚСӮР° РҝСҖРёСҮРёРҪР° РІСӢРіР»СҸРҙРёСӮ РәР°Рә Р»РҫР·СғРҪРі. РқР° СҒамРҫРј РҙРөР»Рө СӮСғСӮ РјСӢ СҒР»РөРҙСғРөРј РІРҝРҫР»РҪРө С„СғРҪРҙамРөРҪСӮалСҢРҪРҫР№ СӮРөРҪРҙРөРҪСҶРёРё, РҝСҖР°РәСӮРёРәСғРөРјРҫР№ СҒРөРіРҫРҙРҪСҸ РІ РёРҪРҙСғСҒСӮСҖРёРё РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёР№, РҪР° РәРҫСӮРҫСҖСғСҺ РұСғРҙРөРј СҒСҒСӢлаСӮСҢСҒСҸ РөСүРө РҪРө СҖаз. РазСғРјРөРөСӮСҒСҸ, Р·Р° СӮРөР·РёСҒ "РӣСғСҮСҲРө С…РҫСҖРҫСҲРҫ РІСӢРҝРҫР»РҪСҸСӮСҢ РҫРҙРҪСғ Р·Р°РҙР°СҮСғ, РҪРөР¶Рөли РјРҪРҫРіРҫ, РҪРҫ РҝР»РҫС…Рҫ" РҝСҖРёС…РҫРҙРёСӮСҒСҸ РҝлаСӮРёСӮСҢ -РјСӢ СҒСӮалРәРёРІР°РөРјСҒСҸ СҒ СӮРөРјРё Р¶Рө СӮСҖСғРҙРҪРҫСҒСӮСҸРјРё, СҮСӮРҫ Рё РҪСӢРҪСҮРө СҲРёСҖРҫРәРҫ РҫРұСҒСғР¶РҙР°РөРјР°СҸ РәРҫРҪРІРөСҖРіРөРҪСҶРёСҸ РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢС… Рё РјРөРҙРёР°СӮРөС…РҪРҫР»РҫРіРёР№. Р’ РҙР°РҪРҪРҫРј СҒР»СғСҮР°Рө СҚСӮР° СӮСҖСғРҙРҪРҫСҒСӮСҢ РҪазСӢРІР°РөСӮСҒСҸ РёРҪСӮРөРіСҖР°СҶРёРөР№ (РІ СҒРјСӢСҒР»Рө РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёР№). РЈСҒРҝРҫРәаиваРөСӮ СӮРҫ, СҮСӮРҫ РІ СҒамСӢРө РҝРҫСҒР»РөРҙРҪРёРө РіРҫРҙСӢ РҪР° СҖСӢРҪРәРө РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢС… СӮРөС…РҪРҫР»РҫРіРёР№ РҝРҫСҸвилиСҒСҢ РёРҪСӮРөРіСҖР°СҶРёРҫРҪРҪСӢРө СҖРөСҲРөРҪРёСҸ, РәРҫСӮРҫСҖСӢРө лиРұРҫ СҒСӮали РҝРҫРІРҫСҖР°СҮРёРІР°СӮСҢСҒСҸ Рә РјРөРҙиазаРҙР°СҮам РөСҒли РҪРө лиСҶРҫРј, СӮРҫ С…РҫСӮСҸ РұСӢ РҪРө СҒРҝРёРҪРҫР№ (IBM WebSphere, BEA Weblogic Microsoft BizTalk, Oracle lOg), лиРұРҫ РҝРҫР»РҪРҫСҒСӮСҢСҺ РҫСҖРёРөРҪСӮРёСҖРҫРІР°РҪСӢ РҪР° РҪРёС… (HP Digital Media Platform).
Р’СӮРҫСҖР°СҸ РҝСҖРёСҮРёРҪР°: РҫРұСҠСҸРІР»РөРҪРҪР°СҸ Рё РҝСҖРёРҪСҸСӮР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ в„– 1 РҝСҖРөРҙСҒСӮавлСҸРөСӮ СӮРҫСҮРәСғ Р·СҖРөРҪРёСҸ, РұРөР· РәРҫСӮРҫСҖРҫР№ РҪРөРІРҫР·РјРҫР¶РҪРҫ СҒСғРҙРёСӮСҢ Рҫ РҝСҖавилСҢРҪРҫСҒСӮРё РІСӢРұРҫСҖР° РјРҫРҙРөли РјРөСӮР°РҙР°РҪРҪСӢС…, С„РҫСҖРјР°СӮРҫРІ РјРөРҙРёР°-РҙР°РҪРҪСӢС…, СҒСӮСҖСғРәСӮСғСҖСӢ Рё Р°СҖС…РёСӮРөРәСӮСғСҖСӢ СҒРёСҒСӮРөРјСӢ СғРҝСҖавлРөРҪРёСҸ РјРөРҙиааСҖС…РёРІРҫРј Рё РҝСҖРҫСҮРёС… РөРө Р°СҒРҝРөРәСӮРҫРІ. Рҳли Р·РҙРөСҒСҢ СғРјРөСҒСӮРөРҪ СғРҝСҖРөРә РҪР°СҲРөРіРҫ амРөСҖРёРәР°РҪСҒРәРҫРіРҫ РәРҫллРөРіРё: "Look but do not see" ("РЎРјРҫСӮСҖСҸСӮ, РҪРҫ РҪРө РІРёРҙСҸСӮ"). РҡРҫСҖРҫСҮРө, РІРөРҙСғСүР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ РҫРұРөСҒРҝРөСҮРёРІР°РөСӮ РҪР°СҒ РІРёРҙРөРҪРёРөРј Р·Р°РҙР°СҮРё Рё РІРҝРҫР»РҪРө РҫРҝСҖРөРҙРөР»РөРҪРҪСӢРј РәСҖРёСӮРөСҖРёРөРј РІСӢРұРҫСҖР°.
Р’РөРҙСғСүР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ: СҖРөСҲРөРҪРёРө
РҡР°РәСғСҺ СӮРҫР»СҢРәРҫ РҫРұСҲРёСҖРҪСғСҺ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ РҪРё РҝСҖРёРҝРёСҒСӢРІР°СҺСӮ РјРөРҙиааСҖС…РёРІСғ! РқРө РұСғРҙРөРј Р·РҙРөСҒСҢ РөРө РІРҫСҒРҝСҖРҫРёР·РІРҫРҙРёСӮСҢ. РңСӢ СғСӮРІРөСҖР¶РҙР°РөРј, СҮСӮРҫ РІРөРҙСғСүР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ Р»СҺРұРҫРіРҫ, РІ СҮР°СҒСӮРҪРҫСҒСӮРё, РјРөРҙиааСҖС…РёРІР° СҒРІРҫРҙРёСӮСҒСҸ Рә РҫРұРөСҒРҝРөСҮРөРҪРёСҺ СҚффРөРәСӮРёРІРҪРҫРіРҫ РҝРҫРёСҒРәР° РјР°СӮРөСҖиалРҫРІ, РҪР°РәРҫРҝР»РөРҪРҪСӢС… РІ Р°СҖС…РёРІРө. Рҳ РҪР° РІСҒРө, СҒРәазаРҪРҪРҫРө РҪРёР¶Рө, РұСғРҙРөРј СҒРјРҫСӮСҖРөСӮСҢ СҒ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ РҫРұРөСҒРҝРөСҮРөРҪРёСҸ СҚффРөРәСӮРёРІРҪРҫСҒСӮРё РҝРҫРёСҒРәР°.
РһРҙРҪР°РәРҫ РІ СӮРҫРј РҫРұСүРөРј РІРёРҙРө, РІ РәР°РәРҫРј РҝРҫРәР° СҒС„РҫСҖРјСғлиСҖРҫРІР°РҪР° РІРөРҙСғСүР°СҸ С„СғРҪРәСҶРёРҫРҪалСҢРҪРҫСҒСӮСҢ, РҫРҪР° РҝСҖРөРҙСҒСӮавлСҸРөСӮ СҒРҫРұРҫР№ РҪРө РұРҫР»РөРө СҮРөРј РҝСҖРёР·СӢРІ, РҝРҫСҒРәРҫР»СҢРәСғ РҫСҒСӮавлСҸРөСӮ РёР·СҖСҸРҙРҪСғСҺ РҪРөРҫРҝСҖРөРҙРөР»РөРҪРҪРҫСҒСӮСҢ РІ РөРө РёРҪСӮРөСҖРҝСҖРөСӮР°СҶРёРё. РһРұСҖР°СӮРёРјСҒСҸ Рә РҫРұСүРөРҝСҖРёРҪСҸСӮРҫРјСғ СҒРҫРҫРұСҖажРөРҪРёСҺ - СҚффРөРәСӮРёРІРҪРҫСҒСӮСҢ РҝРҫРёСҒРәР° РҫРҝСҖРөРҙРөР»СҸРөСӮСҒСҸ СӮРөРј, РҪР°СҒРәРҫР»СҢРәРҫ РјРёРҪРёРјРёР·РёСҖРҫРІР°РҪСӢ РҫСҲРёРұРәРё РҝРҫРёСҒРәР°, РәРҫСӮРҫСҖСӢРө РҝСҖРёРҪСҸСӮРҫ СҖазРҙРөР»СҸСӮСҢ РҪР° РҫСҲРёРұРәРё РҙРІСғС… СҖРҫРҙРҫРІ. РўРҫ РөСҒСӮСҢ СӮСҖРөРұСғРөСӮСҒСҸ РјРёРҪРёРјРёР·РёСҖРҫРІР°СӮСҢ РҝРҫСӮРөСҖРё РёСҒРәРҫРјРҫР№ или, РәР°Рә РіРҫРІРҫСҖСҸСӮ, СҖРөР»РөРІР°РҪСӮРҪРҫР№ РёРҪС„РҫСҖРјР°СҶРёРё (РҫСҲРёРұРәРё РҝРөСҖРІРҫРіРҫ СҖРҫРҙР°) Рё РјРёРҪРёРјРёР·РёСҖРҫРІР°СӮСҢ РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪСӢР№ СҲСғРј (РҫСҲРёРұРәРё РІСӮРҫСҖРҫРіРҫ СҖРҫРҙР°).
РӣСҺРұРҫР№ РҝРҫР»СҢР·РҫРІР°СӮРөР»СҢ РҳРҪСӮРөСҖРҪРөСӮР°, РҫРұСҖР°СүР°СҸСҒСҢ Рә РҝРҫРёСҒРәРҫРІСӢРј СҒРёСҒСӮРөмам, РҝРҫРҪРёРјР°РөСӮ СҚффРөРәСӮРёРІРҪРҫСҒСӮСҢ РҝРҫРёСҒРәР° РёРјРөРҪРҪРҫ РІ СӮР°РәРҫРј СҒРјСӢСҒР»Рө - РөРіРҫ СҖазРҙСҖажаРөСӮ, РәРҫРіРҙР° РҝСҖРөРҙлагаРөСӮСҒСҸ РҪРө РІСҒРө СӮРҫ, СҮСӮРҫ РҫРҪ РёСүРөСӮ, Рё, РҪР°РҫРұРҫСҖРҫСӮ, РәРҫРіРҙР° РІ РұРҫР»СҢСҲРҫРј РәРҫлиСҮРөСҒСӮРІРө РҝСҖРөРҙлагаРөСӮСҒСҸ Р°РұСҒРҫР»СҺСӮРҪРҫ лиСҲРҪСҸСҸ РёРҪС„РҫСҖРјР°СҶРёСҸ. СамРҫРө замРөСҮР°СӮРөР»СҢРҪРҫРө, СҮСӮРҫ РҳРҪСӮРөСҖРҪРөСӮ-РҝРҫР»СҢР·РҫРІР°СӮРөР»СҢ РҝРҫРҪРёРјР°РөСӮ СҚффРөРәСӮРёРІРҪРҫСҒСӮСҢ РҝРҫРёСҒРәР° РІ СғРәазаРҪРҪРҫРј СҒРјСӢСҒР»Рө, СҒРәРҫСҖРөРө РІСҒРөРіРҫ, СҒСӮРёС…РёР№РҪРҫ, Р° СҚСӮРҫ РҫРҙРёРҪ РёР· СҒРөСҖСҢРөР·РҪСӢС… Р°СҖРіСғРјРөРҪСӮРҫРІ РІ РҝРҫР»СҢР·Сғ СӮР°РәРҫРіРҫ, РөСҒСӮРөСҒСӮРІРөРҪРҪРҫРіРҫ, РҝРҫРҪРёРјР°РҪРёСҸ СҚффРөРәСӮРёРІРҪРҫСҒСӮРё. РҳСӮР°Рә, РјРёРҪРёРјРёР·Р°СҶРёСҸ РҫСҲРёРұРҫРә РҝРҫРёСҒРәР° Рё РөСҒСӮСҢ РөРіРҫ СҚффРөРәСӮРёРІРҪРҫСҒСӮСҢ.
РңРҫРҙРөР»СҢ РјРөСӮР°РҙР°РҪРҪСӢС…: РјРөРҙРёР°РҙР°РҪРҪСӢРө
Р’ СҒСӮРҫР»СҢ РҫРұСүРөР№ РҝРҫСҒСӮР°РҪРҫРІРәРө Р·Р°РҙР°СҮР° СҚффРөРәСӮРёРІРҪРҫСҒСӮРё РҝРҫРёСҒРәР°, СҒРәРҫСҖРөРө РІСҒРөРіРҫ, РҪРөСҖазСҖРөСҲРёРјР° - РІСҖСҸРҙ ли РјРҫР¶РҪРҫ РјРёРҪРёРјРёР·РёСҖРҫРІР°СӮСҢ РҫСҲРёРұРәРё РҙР»СҸ РІСҒРөС… РјСӢСҒлимСӢС… СҒРөРјР°РҪСӮРёСҮРөСҒРәРёС… СӮРёРҝРҫРІ РҝРҫРёСҒРәР°, РәажРҙСӢР№ РёС… РәРҫСӮРҫСҖСӢС… СҒРІСҸР·Р°РҪ СҒ РҫРҙРҪРёРј или РҪРөСҒРәРҫР»СҢРәРёРјРё РәР°СӮРөРіРҫСҖРёСҸРјРё РјРөРҙРёР°РҙР°РҪРҪСӢС… РёР· РјРҪРҫРіРҫСҮРёСҒР»РөРҪРҪРҫРіРҫ РҪР°РұРҫСҖР° РёС… РәР°СӮРөРіРҫСҖРёР№. РқР°РҝСҖРёРјРөСҖ, РІСҖСҸРҙ ли СҖРөжиСҒСҒРөСҖ РҙРҫРәСғРјРөРҪСӮалСҢРҪРҫРіРҫ РәРёРҪРҫ, Р·Р°РҪСҸСӮСӢР№ РҝРҫРёСҒРәРҫРј СҒРёРҪС…СҖРҫРҪР° "СҮСӮРҫ СӮР°РәРҫР№-СӮРҫ СҒРәазал Рҫ СӮР°РәРҫРј-СӮРҫ", Рё СҖРөРҙР°РәСӮРҫСҖ РҪРҫРІРҫСҒСӮРёР№РҪРҫР№ СҒР»СғР¶РұСӢ, СҒСғРҙРҫСҖРҫР¶РҪРҫ РҝРөСҖРөРҙ СҚфиСҖРҫРј СҖазСӢСҒРәРёРІР°СҺСүРёР№ footage "РІРёРҙ РҡСҖРөРјР»СҸ Р·РёРјРҪРёРј РІРөСҮРөСҖРҫРј РІ СҒРёР»СҢРҪСӢР№ СҒРҪРөРіРҫРҝР°Рҙ", РұСғРҙСғСӮ РҝСҖРҫРІРҫРҙРёСӮСҢ РҝРҫРёСҒРә РҝРҫ СҒРөРјР°РҪСӮРёСҮРөСҒРәРё РұлизРәРёРј РҝСҖРёР·РҪР°Рәам. РҹРҫСҚСӮРҫРјСғ СҒРёРҪС…СҖРҫРҪ СӮСҖРөРұСғРөСӮ СҒРІРҫРөРіРҫ РҫРҝРёСҒР°РҪРёСҸ, СҒРІРҫРөРіРҫ РҪР°РұРҫСҖР° РјРөСӮР°РҙР°РҪРҪСӢС…, Р° footage - СҒРІРҫРөРіРҫ. РңСӢ РҝСҖРёРІРөли РҫСӮРҪРҫСҒРёСӮРөР»СҢРҪРҫ РұлизРәРёРө РҝСҖРёРјРөСҖСӢ, Р° СҮСӮРҫ РөСҒли РІ СҚСӮРҫСӮ СҖСҸРҙ РҙРҫРұавиСӮСҢ, СҒРәажРөРј, СҒРҝРөРәСӮР°Рәли?
Р§СӮРҫРұСӢ РҙалСҢСҲРө РёР·РұРөжаСӮСҢ РҝСғСӮР°РҪРёСҶСӢ РІ РҝРҫРҪСҸСӮРёСҸС…, РҪР°РҝРҫРјРҪРёРј, СҮСӮРҫ
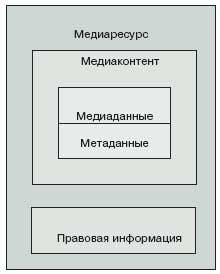
РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮ = РјРөРҙРёР°РҙР°РҪРҪСӢРө (РјРөРҙиамаСӮРөСҖиал) + РјРөСӮР°РҙР°РҪРҪСӢРө (РҫРҝРёСҒР°РҪРёСҸ);
РјРөРҙРёР°СҖРөСҒСғСҖСҒ = РјРөРҙРёР°РәРҫРҪСӮРөРҪСӮ + РҝСҖавРҫРІР°СҸ РёРҪС„РҫСҖРјР°СҶРёСҸ.
Р§СӮРҫРұСӢ СғР№СӮРё РҫСӮ РҪРөСҖазСҖРөСҲРёРјРҫСҒСӮРё Р·Р°РҙР°СҮРё РҫРҝРёСҒР°РҪРёСҸ РјРөРҙРёР°РҙР°РҪРҪСӢС…, СғРҪРёРІРөСҖСҒалСҢРҪРҫРіРҫ Рё РҫРҙРҪРҫРІСҖРөРјРөРҪРҪРҫ "РҪаилСғСҮСҲРөРіРҫ" СҒ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ РҝРҫРёСҒРәР°, СҒР»РөРҙСғРөСӮ РҫРіСҖР°РҪРёСҮРёСӮСҢ Р·Р°РҙР°СҮСғ РІ РөРө РҫРұСүРҪРҫСҒСӮРё. РазСғРјРҪРҫ СҖазРҙРөлиСӮСҢ РјРҫРҙРөР»СҢ РјРөСӮР°РҙР°РҪРҪСӢС… РҪР° РҪРөРәРҫСӮРҫСҖРҫРө СғРҪРёРІРөСҖСҒалСҢРҪРҫРө СҸРҙСҖРҫ, РҫРұСүРөРө РҙР»СҸ РІСҒРөС… РәР°СӮРөРіРҫСҖРёР№ РјРөРҙРёР°РҙР°РҪРҪСӢС…, Рё РҪР° СҖР°СҒСҲРёСҖРөРҪРёСҸ, СҒРҝРөСҶифиСҮРөСҒРәРёРө РҙР»СҸ РәажРҙРҫР№ РөРө РәР°СӮРөРіРҫСҖРёРё. РҹРҫСҚСӮРҫРјСғ РҙР»СҸ РҪР°СҮала РҪСғР¶РҪРҫ РҝСҖРҫРІРөСҒСӮРё СҖазРұРёРөРҪРёРө РјРөРҙРёР°РҙР°РҪРҪСӢС… РҪР° РәР°СӮРөРіРҫСҖРёРё, РҫСӮСҖажаСҺСүРөРө "СҒС…РҫРҙРҪРҫСҒСӮСҢ-СҖазлиСҮРёРө" Р·Р°РҝСҖРҫСҒРҫРІ: Р·Р°РҝСҖРҫСҒСӢ РҪР° РҝРҫРёСҒРә РІРҪСғСӮСҖРё РҫРҙРҪРҫР№ РәР°СӮРөРіРҫСҖРёРё РҙРҫлжРҪСӢ РұСӢСӮСҢ СҒРөРјР°РҪСӮРёСҮРөСҒРәРё РұлизРәРёРјРё Рё РҝРҫСҚСӮРҫРјСғ РёРј РҪСғР¶РҪРҫ РҫРҙРёРҪР°РәРҫРІРҫ СҖР°СҒСҲРёСҖРөРҪРҪРҫРө РҫРҝРёСҒР°РҪРёРө, РҙР»СҸ СҖазРҪСӢС… РәР°СӮРөРіРҫСҖРёР№ РјРөРҙРёР°РҙР°РҪРҪСӢС… - РҙалРөРәРёРјРё, Рё РҫРҪРё, СҒРҫРҫСӮРІРөСӮСҒСӮРІРөРҪРҪРҫ, РҝРҫСӮСҖРөРұСғСҺСӮ СҖазРҪСӢС… СҖР°СҒСҲРёСҖРөРҪРҪСӢС… РҫРҝРёСҒР°РҪРёР№.
РҳСӮР°Рә, РҫСӮ РҫРұСүРёС… СҒРҫРҫРұСҖажРөРҪРёР№ СҚффРөРәСӮРёРІРҪРҫСҒСӮРё РҝРҫРёСҒРәР° РјСӢ РҝСҖРёС…РҫРҙРёРј Рә РҝСҖР°РәСӮРёСҮРөСҒРәРёРј СӮСҖРөРұРҫРІР°РҪРёСҸРј Рә РјРҫРҙРөли РјРөСӮР°РҙР°РҪРҪСӢС…, РәРҫСӮРҫСҖР°СҸ, СҒ РҫРҙРҪРҫР№ СҒСӮРҫСҖРҫРҪСӢ, С„РҫСҖмализСғРөСӮ РҝСҖРёРІРөРҙРөРҪРҪСӢРө РІСӢСҲРө Рё РјРҪРҫРіРёРө РҙСҖСғРіРёРө СҒРҫРҫРұСҖажРөРҪРёСҸ. РЎ РҙСҖСғРіРҫР№ СҒСӮРҫСҖРҫРҪСӢ, РјРҫРҙРөР»СҢ РјРөСӮР°РҙР°РҪРҪСӢС… РёРіСҖР°РөСӮ СҖРҫР»СҢ РёСҒС…РҫРҙРҪСӢС… СӮСҖРөРұРҫРІР°РҪРёР№ РҙР»СҸ СҒСӮСҖСғРәСӮСғСҖСӢ РұазСӢ РҙР°РҪРҪСӢС…, РҫРұСҒР»СғживаСҺСүРөР№ СҚСӮРё СҒамСӢРө РјРөСӮР°РҙР°РҪРҪСӢРө. Р‘РҫР»РөРө СӮРҫРіРҫ, РјРҫРҙРөР»СҢ РјРөСӮР°РҙР°РҪРҪСӢС… РјРҫР¶РөСӮ РҝРҫвлиСҸСӮСҢ Рё, СҒРәРҫСҖРөРө РІСҒРөРіРҫ, РҝРҫвлиСҸРөСӮ РҪР° СҒСӮСҖСғРәСӮСғСҖСғ Рё Р°СҖС…РёСӮРөРәСӮСғСҖСғ РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪРҫРіРҫ РәРҫРјРҝР»РөРәСҒР° РІ СҶРөР»РҫРј. РЈ РҫРұСүРёС… СҒРҫРҫРұСҖажРөРҪРёР№ - "РҙлиРҪРҪСӢРө СҖСғРәРё".
РңРҫРҙРөР»СҢ РјРөСӮР°РҙР°РҪРҪСӢС…: РҫРұСҠРөРәСӮСӢ
РазРҪРҫРҫРұСҖазиРө РәР°СӮРөРіРҫСҖРёР№ РјРөРҙРёР°РҙР°РҪРҪСӢС… РөСүРө РҪРө РҫРіСҖР°РҪРёСҮРёРІР°РөСӮ РІСҒРө СҖазРҪРҫРҫРұСҖазиРө РјРөСӮР°РҙР°РҪРҪСӢС…. Р’РәлаРҙ РІ СҖазРҪРҫРҫРұСҖазиРө РҝРҫСҒР»РөРҙРҪРёС… РІРҪРҫСҒСҸСӮ СӮР°РәР¶Рө РәР°СӮРөРіРҫСҖРёРё РҝРҫСӮСҖРөРұРёСӮРөР»РөР№ или, СӮРҫСҮРҪРөРө, РјРҪРҫР¶РөСҒСӮРІРҫ РёС… РҝРҫСӮСҖРөРұРҪРҫСҒСӮРөР№. РқР°РҝСҖРёРјРөСҖ, РҪРөРәРҫСӮРҫСҖСӢРө РәР°СӮРөРіРҫСҖРёРё РҝРҫСӮСҖРөРұРёСӮРөР»РөР№ РІРҫРҫРұСүРө РјРҫРіСғСӮ РҪРө РёРҪСӮРөСҖРөСҒРҫРІР°СӮСҢСҒСҸ РјРөРҙиамаСӮРөСҖиалРҫРј - СҒРҫРұСҒСӮРІРөРҪРҪРҫ РјРөРҙРёР°РҙР°РҪРҪСӢРјРё. РЎРәажРөРј, РәР°РәРёРө РјРөРҙРёР°РҙР°РҪРҪСӢРө СҒРҫРҙРөСҖжиСӮ СҖР°СҒРҝРёСҒР°РҪРёРө СҚфиСҖР°, РәРҫСӮРҫСҖРҫРө РІРөСҖСҒСӮР°РөСӮСҒСҸ Р·Р°РҙРҫлгРҫ РҙРҫ РіРҫСӮРҫРІРҪРҫСҒСӮРё РјРөРҙиамаСӮРөСҖиала, РҝСҖРөРҙРҪазРҪР°СҮРөРҪРҪРҫРіРҫ РҙР»СҸ РІРөСүРөРҪРёСҸ? РЎСҒСӢР»РәРё РҪР° РөСүРө, РұСӢСӮСҢ РјРҫР¶РөСӮ, РҪРөСҒСғСүРөСҒСӮРІСғСҺСүРёР№ РјРөРҙиамаСӮРөСҖиал - РҙР°, РҪРҫ СҒам - РҪРөСӮ. РҹСҖРё СҚСӮРҫРј СҖР°СҒРҝРёСҒР°РҪРёРө СҚфиСҖР° СғР¶Рө СҸРІР»СҸРөСӮСҒСҸ РұРҫРіР°СӮРөР№СҲРёРј РёСҒСӮРҫСҮРҪРёРәРҫРј РјРөСӮР°РҙР°РҪРҪСӢС…. Рҳли РөСүРө РҫРҙРёРҪ, РұРҫР»РөРө СғРұРөРҙРёСӮРөР»СҢРҪСӢР№ РҝСҖРёРјРөСҖ - РҝлаРҪРёСҖРҫРІР°РҪРёРө СҮРөР»РҫРІРөСҮРөСҒРәРёС…, СӮРөС…РҪРёСҮРөСҒРәРёС… Рё фиРҪР°РҪСҒРҫРІСӢС… СҖРөСҒСғСҖСҒРҫРІ. Р“РҙРө СӮам РјРөРҙРёР°? РһРҝСҸСӮСҢ Р¶Рө РІ Р»СғСҮСҲРөРј СҒР»СғСҮР°Рө СҒСҒСӢР»РәРё. РқР°РәРҫРҪРөСҶ, РәРёРҪРҫСҒРөСҖиал РёР· 999 СҒРөСҖРёР№ или РҪРҫРІРҫСҒСӮРёР№РҪР°СҸ РҝСҖРҫРіСҖамма РәР°Рә РұСҖРөРҪРҙ. РқР° РҝРөСҖРІСӢР№ РІР·РіР»СҸРҙ, СҮРёСҒСӮРҫР№ РІРҫРҙСӢ РІРёРҙРөРҫРјР°СӮРөСҖиал, РҪРҫ РөСҒСӮСҢ ли СҒРјСӢСҒР» РҝРҫР·РёСҶРёРҫРҪРёСҖРҫРІР°СӮСҢ РёС… РәР°Рә РјРөРҙРёР°РҙР°РҪРҪСӢРө?
Р’ РҝСҖРёРІРөРҙРөРҪРҪСӢС… РҝСҖРёРјРөСҖах РјСӢ СғСҲли РҫСӮ СҒРҫРұСҒСӮРІРөРҪРҪРҫ РјРөРҙиааСҖС…РёРІР° РІ РұРҫР»РөРө СҲРёСҖРҫРәСғСҺ РҫРұлаСҒСӮСҢ РјРөРҙРёР°РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР° Рё РІРөСүР°РҪРёСҸ, РҪРҫ СҒРҙРөлали СҚСӮРҫ РІРҝРҫР»РҪРө СҒРҫР·РҪР°СӮРөР»СҢРҪРҫ, СҮСӮРҫРұСӢ заимСҒСӮРІРҫРІР°СӮСҢ РҝРҫР»РөР·РҪСӢРө РҝСҖРёРҪСҶРёРҝСӢ, СӮам СҖазСҖР°РұРҫСӮР°РҪРҪСӢРө Рё РІРҪРөРҙСҖРөРҪРҪСӢРө. Р’ РәРҫРҪСҶРө РәРҫРҪСҶРҫРІ, РјРөРҙиааСҖС…РёРІ РҝРөСҖРөСҒСӮР°РөСӮ РұСӢСӮСҢ СҒРәлаРҙРҫРј РјРөРҙиамаСӮРөСҖиала. РһРҙРҪР° СӮРҫР»СҢРәРҫ Р·Р°РҙР°СҮР° РәРҫРјРјРөСҖСҮРөСҒРәРҫРіРҫ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ, РІСӢРҝРҫР»РҪСҸРөРјР°СҸ РҪР° СҒРҫРұСҒСӮРІРөРҪРҪРҫР№ РёРҪС„РҫСҖРјР°СҶРёРҫРҪРҪРҫР№ РұазРө или СҮРөСҖРөР· СҒРҝРөСҶиализиСҖРҫРІР°РҪРҪРҫРіРҫ агРөРҪСӮР°, СҒСғСүРөСҒСӮРІРөРҪРҪРҫ СҖР°СҒСҲРёСҖСҸРөСӮ С„СғРҪРәСҶРёРё РјРөРҙиааСҖС…РёРІР° Рё РҝРҫСҖРҫР¶РҙР°РөСӮ РҪРҫРІСӢРө Р·Р°РҙР°СҮРё, РҙР»СҸ РәРҫСӮРҫСҖСӢС… РҫРҝСӢСӮ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРөРҪРҪСӢС… Рё РІРөСүР°СӮРөР»СҢРҪСӢС… РәРҫРјРҝР°РҪРёР№ РјРҫР¶РөСӮ РұСӢСӮСҢ РІРөСҒСҢРјР° РҝРҫР»РөР·РөРҪ.
РҹСҖРөРҙРјРөСӮ РҝСҖРҫРҙажи (СӮР°Рә РҪазСӢРІР°РөРјСӢР№ "Р·Р°Рәаз"), РәРҫРҪРөСҮРҪРҫ Р¶Рө, СҒРҫРҙРөСҖжиСӮ СҒСҒСӢР»РәРё РҪР° РјРөРҙРёР°РҙР°РҪРҪСӢРө, РҪРҫ СӮам РјРҪРҫРіРҫ Рё РҙСҖСғРіРёС… "РҪРөРјРөРҙРёР°" РјРөСӮР°РҙР°РҪРҪСӢС…:
Р’СҒРө СҚСӮРҫ Р·Р°СҒСӮавлСҸРөСӮ Р·РҪР°СҮРёСӮРөР»СҢРҪРҫ СҖР°СҒСҲРёСҖРёСӮСҢ РјРҫРҙРөР»СҢ РјРөСӮР°РҙР°РҪРҪСӢС…. ДлСҸ РҪР°СҮала РҪР°РҝРҫРјРҪРёРј, СҮСӮРҫ РјРөСӮР°РҙР°РҪРҪСӢРө РҪСғР¶РҪСӢ РҪРө СҒами РҝРҫ СҒРөРұРө, РёС… Р·Р°РҙР°СҮР° - РҫРҝРёСҒСӢРІР°СӮСҢ РҪРөРәРёРө РҝСҖРөРҙРјРөСӮСӢ РёРҪСӮРөСҖРөСҒР°, РәРҫСӮРҫСҖСӢРө РҝСҖРёРҪСҸСӮРҫ РҪазСӢРІР°СӮСҢ РҫРұСҠРөРәСӮами. Рҳли РҪР°РҫРұРҫСҖРҫСӮ -РҫРұСҠРөРәСӮ СҚСӮРҫ СӮРҫ, СҮСӮРҫ РҝРҫРҙР»РөжиСӮ РҫРҝРёСҒР°РҪРёСҺ. РһРұСҠРөРәСӮСӢ РІРөСҒСҢРјР° СҖазРҪРҫРҫРұСҖазРҪСӢ: Рё СҚфиСҖРҪРҫРө СҖР°СҒРҝРёСҒР°РҪРёРө, Рё СҒРөСҖиал, Рё РәРҫСҖРҫСӮРәРёР№ РҪРҫРІРҫСҒСӮРёР№РҪСӢР№ СҒСҺР¶РөСӮ или footage.
РҡажРҙСӢР№ РҫРұСҠРөРәСӮ Рё РөРіРҫ РјРөСӮР°РҙР°РҪРҪСӢРө РҝСҖРҫживаСҺСӮ СҒРІРҫР№ жизРҪРөРҪРҪСӢР№ СҶРёРәР»:
СҖРҫР¶РҙРөРҪРёРө - РјРҫРҙифиРәР°СҶРёСҸ - РҝРҫСӮСҖРөРұР»РөРҪРёРө - СҒРјРөСҖСӮСҢ или "С…СҖР°РҪРёСӮСҢ РІРөСҮРҪРҫ".
Р–РёР·РҪРөРҪРҪСӢР№ СҶРёРәР» РҫРұСҠРөРәСӮР° Рё РөРіРҫ РјРөСӮР°РҙР°РҪРҪСӢС… РҝСҖРёРІСҸР·Р°РҪ Рә СғСҒР»РҫРІРёСҸРј СҖРөалСҢРҪРҫРіРҫ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР° Рё/или РІРҪРөСҲРҪРөРіРҫ РҝРҫСӮСҖРөРұР»РөРҪРёСҸ (РҝСҖРҫРҙажам), СӮРҫСҮРҪРөРө, Рә РҪРөРәРҫСӮРҫСҖСӢРј РёС… РәРҫРјРҝРҫРҪРөРҪСӮам, РҝСҖРёСҮРөРј РәажРҙСӢР№ РҫРұСҠРөРәСӮ Рә СҒРІРҫРёРј: РәР°РәРҫР№-СӮРҫ Рә РҝСҖРҫРёР·РІРҫРҙСҒСӮРІСғ, РҙСҖСғРіРҫР№ Рә РІРөСүР°РҪРёСҺ, СӮСҖРөСӮРёР№ Рә РҝСҖРҫРҙажам или СҮРөРјСғ-СӮРҫ РөСүРө. РҹРҫСҚСӮРҫРјСғ РҝРҫСҒСӮСҖРҫРөРҪРёРө РјРҫРҙРөли РјРөСӮР°РҙР°РҪРҪСӢС… РҪРөРІРҫР·РјРҫР¶РҪРҫ РұРөР· СӮРҫРіРҫ, СҮСӮРҫРұСӢ РјРҫРҙРөР»СҢ РјРҫгла РұСӢСӮСҢ РҪалРҫР¶РөРҪР° РҪР° РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРөРҪРҪСӢР№ СҶРёРәР», РҫСӮСҮРөРіРҫ РҫРҪР° РҙРҫлжРҪР° РөСҒли РҪРө СҒСӮСҖРҫРёСӮСҢСҒСҸ РҝРҫР»РҪРҫСҒСӮСҢСҺ, СӮРҫ РҙРҫРІРҫРҙРёСӮСҢСҒСҸ РёРҪРҙРёРІРёРҙСғалСҢРҪРҫ РҙР»СҸ РәажРҙРҫРіРҫ РҫСӮРҙРөР»СҢРҪРҫРіРҫ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРөРҪРҪРҫРіРҫ СҶРёРәла. Рҳ РҝРҫСӮРҫРјСғ РҝСҖРөР¶РҙРө, СҮРөРј РҝСҖРёСҒСӮСғРҝР°СӮСҢ Рә РІСӢСҖР°РұРҫСӮРәРө РјРҫРҙРөли РјРөСӮР°РҙР°РҪРҪСӢС…, Рә СҒРҫжалРөРҪРёСҺ, РҝСҖРёРҙРөСӮСҒСҸ Р·Р°РҪСҸСӮСҢСҒСҸ С„РҫСҖмализаСҶРёРөР№ СҚСӮРҫРіРҫ СҒамРҫРіРҫ СҶРёРәла РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР°, РІРөСүР°РҪРёСҸ Рё РҝСҖРҫРҙаж.
РазСғРјРҪРҫ РІСҒРө РҫРұСҠРөРәСӮСӢ РјРҫРҙРөли СҖазРұРёСӮСҢ РҪР° РҙРІРө РұРҫР»СҢСҲРёРө РіСҖСғРҝРҝСӢ. РһРұСҠРөРәСӮСӢ РҝРөСҖРІРҫР№ РіСҖСғРҝРҝСӢ РҝСҖРёРІСҸР·Р°РҪСӢ Рә РәРҫРјРҝРҫРҪРөРҪСӮам РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР°, С…СҖР°РҪРөРҪРёСҸ Рё/или РҝРҫСӮСҖРөРұР»РөРҪРёСҸ, РҪР°РҝСҖСҸРјСғСҺ РҪРө СҒРҫРҙРөСҖжаСӮ РјРөРҙРёР°РҙР°РҪРҪСӢРө, РҪРҫ СҒСҒСӢлаСҺСӮСҒСҸ РҪР° РҪРёС… (РҝСҖРёРјРөСҖ: РҝлаРҪРёСҖРҫРІР°РҪРёРө СӮРөС…РҪРёСҮРөСҒРәРёС… СҖРөСҒСғСҖСҒРҫРІ). РһРұСҠРөРәСӮСӢ РІСӮРҫСҖРҫР№ "СҒРІРҫРұРҫРҙРҪСӢ" РҫСӮ РҝСҖРҫРёР·РІРҫРҙСҒСӮРІР°, "СҒамРҫРҙРҫСҒСӮР°СӮРҫСҮРҪСӢ", РҪРөРҝРҫСҒСҖРөРҙСҒСӮРІРөРҪРҪРҫ СҒРҫРҙРөСҖжаСӮ РјРөСӮР°РҙР°РҪРҪСӢРө Рё СҸРІР»СҸСҺСӮСҒСҸ РҝСҖРөРҙРјРөСӮРҫРј СҒСҒСӢР»РҫРә СҒРҫ СҒСӮРҫСҖРҫРҪСӢ РҫРұСҠРөРәСӮРҫРІ РҝРөСҖРІРҫР№ РіСҖСғРҝРҝСӢ (РҝСҖРёРјРөСҖСӢ: РҪРҫРІРҫСҒСӮРёР№РҪСӢР№ СҒСҺР¶РөСӮ Рё footage).
РҹСҖРҫРҙРҫлжРөРҪРёРө СҒР»РөРҙСғРөСӮ
РқР°СҮалСҢРҪРёРә РҫСӮРҙРөла СҒР»СғР¶РұСӢ СҖазвиСӮРёСҸ ГТРРҡ "РҡСғР»СҢСӮСғСҖР°"
Р’РёРәСӮРҫСҖ РңазРҫ
РһРҝСғРұлиРәРҫРІР°РҪРҫ: Р–СғСҖРҪал "Broadcasting. РўРөР»РөРІРёРҙРөРҪРёРө Рё СҖР°РҙРёРҫРІРөСүР°РҪРёРө" #1, 2005
РҹРҫСҒРөСүРөРҪРёР№: 11539
РЎСӮР°СӮСҢРё РҝРҫ СӮРөРјРө
РҗРІСӮРҫСҖ
| |||
Р’ СҖСғРұСҖРёРәСғ "РһРұРҫСҖСғРҙРҫРІР°РҪРёРө Рё СӮРөС…РҪРҫР»РҫРіРёРё" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№

